向着芯片间串行以及背板互连方向转变的潮流,继续以惊人的步伐前进,尤其在通信和存储领域。 诸如OIF、Rapid I/O TA以及PCI-SIG等的标准化组织已经巩固了它们的成果,多种基于信息包的协议正在被系统和芯片供应商所采纳。正如这些已经建立的新标准的物理层和协议层,系统供应商现在不得不决定如何最佳地将这些新的协议转换到已有的传输结构上,包括板间和板内。
在标准委员会会议上常见的讨论总是围绕着最佳的方案以使得这些串行标准能够经济地在实际的电路板和底板上实现,并且着重考虑尽可能地重新使用现有的传输结构。在通信行业,在PCB板上采用FR-4用于短距离的芯片间和背板间通信,以及采用电缆(coax, CAT5/5E/6)用于长距离、板间或底板间的通信是迄今为止最流行的选择。
一些行动突出了长距离电缆传输的重要性:诸如PCI Express Cabling工作组预计在2005年第一季度发布一项规范。与此同时,因为 系统供应商第一次在样机上实现协议,并且寻找在标准功能上实现专利逻辑的灵活性,所以这些协议基于FPGA的实现不久将问世。
本文考察了这几种新兴串行I/O标准,尤其是有线和无线网络领域,并且探讨一些基于FPGA的SERDES实现以及由莱迪思半导体公司和泰科电子公司开发的电缆传输构架。
新兴的串行标准和基于SERDES FPGA器件的实现
SERDES品质的重要性
设计者常常面临将大块的数据以较高的速率从一个地方移送到相隔一定距离的另一个地方。长久以来,这是通过同步并行接口来完成的。这一接口需要大量的并行线驱动器和接收器。此外,要确保当今系统所要求的、以吉比特以上的数据率在板间传送的这类接口的数据完整性变得日益困难。
随着对串行器/解串器(SERDES)器件接受的增长,设计者能够较少考虑与并行接口实现相关的问题。SERDES技术可以采用更小、更便宜的电缆和连接器,在以3.125Gbps或更高的速率移动大量的数据块的情况下,为信号的完整性提供更强大的解决方案。
然而,提供一个强大的SERDES解决方案远远不只是原始数据率。若要真正地评定一个SERDES的性能,必须还要考虑物理层的参数,诸如高数据率下的媒体类型/驱动长度,信号的抖动以及整个器件的功耗等。
鉴于以下原因,Lattice SERDES被认为是业界领先的产品:
- 驱动长度(通过无源信道) - (在3.125Gbps下, >40英寸的FR-4背板,10米的24 AWG 电缆)
- 抖动 - (Tx/Rx 抖动值 (分别为.17 UI / .75 UI) 超过XAUI和FC的抖动规范)
- 功率 - (最坏的情况下, 3.125Gbps时225mW/信道, 包括I/O缓冲器)
- 灵活性 - (每个信道可选择全数据率或者半数据率)
除了一个合格的SERDES外,它还必须提供与物理编码子层(PCS)有关的功能,这是为了兼容一些工业标准所必备的。这些标准包括:已有的基于信息包的工业标准,诸如PCI Express, Serial Rapid I/O,以及正在形成的标准,诸如CPRI和OBSAI。莱迪思半导体公司的ORCA 4系列的FPSC(现场可编程系统芯片)器件提供了这样的一种解决方案,它把业界领先的SERDES技术和更高层的PCS逻辑结合在一起。这些用ASIC技术实现的嵌入式的核,与FPGA结构被集成到同一块芯片上,创造出高性能、低功耗的系统级解决方案。
可编程功能的价值
对于任何一种新生的标准或技术,实现的开始比其规范的最终版本的出台要早得多。而且,厂商们很少严格地遵照这些规范,取而代之的是使其系统利用专有的电路来增强规范中所倡导的功能 …… 一种在最终的产品中增加其自身特色的方法。
独立的专用标准产品(ASSP)的优点是容易用文件说明并且易懂,但是对于牵涉到新生规范的应用,对设计者而言,可编程能力是一大优势。可编程能力能够让系统设计者在无需等待规范的最终版本的情况下,尽早地开始构架并实施他们的设计。莱低思FPSC的ASIC部分提供了针对设计的成熟部分的性能和功率上的优势(例如,带有8b/10b编码的SERDES),FPSC器件的可编程本性能让设计的上层跟随规范和客户的需求而“更新”。
以下是多个标准和应用的实例,它们非常适合采用集成的ASIC/FPGA技术。
无线网络:PCI Express和Rapid I/O
PCI Express
传统的PCI,在九十年代早期确立的标准I/O总线,现在已显陈旧。这样就导致了设计者采用诸如PCI-x和PCI-x 2.0等更新的版本来实现。它们能让设计者在现有软件的基础上达到更高的吞吐量。但是即便有了这些改进,处理器的吞吐量仍然超过了I/O的吞吐量。
PCI Express 的构想是为了处理这些不断增长的带宽需求。它提供了一个可升级的、点到点的芯片间的串行连接,通过电缆或连结器插槽来扩展卡,并且在软件层上保持与传统的PCI的兼容性。
单个PCI Express的串行连接是一个对偶单纯形链路,指定的速度高达每个链路2.5Gbps。该链路可以被扩展成x1, x2, x4, x8, x12, x16信道宽度,从而达到更高的带宽。串行实现较为便宜,可以用来驱动较长的距离、减小共模噪声以及现有的源同步并行接口所固有的相偏(诸如传统的PCI),并且减少所需的连接总数。出于实用的目的,本文将探讨用标准电缆连接器实现的信道宽度。
如图1所示,PCI Express是一个经过打包和分层的协议结构。来自莱迪思半导体公司的ORTx2G5器件,外加内嵌的ASIC和软IP核(图1中的功能块),提供了一种低成本、低功耗、高度集成的解决方案。它用于PCI Express规范的物理层和数据链路层。
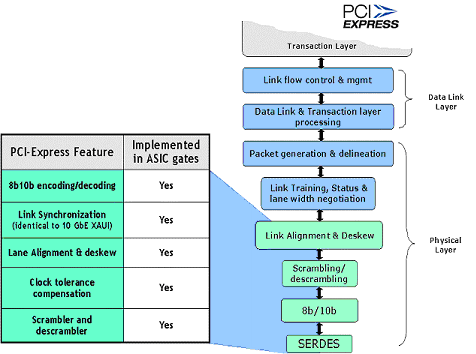
图 1 – PCI Express协议栈的实现
本文已经提到了在实现这些新生标准时,可编程解决方案的价值。PCI Express栈的数据链路层和处理层都是可编程性的优点的很好例证。
根据设计,这些层可以被定制成支持一个终端实现、一个交换机,或者,在有FPGA介入的很多情况下,一种用于诸如传统的PCI的遗留通信协议的桥接功能。
通过在ASIC门中实现物理层和数据链路层的固定功能,以及在FPGA门中由用户实现更高层的功能,系统设计者有了一种经济且可配置的PCI Express解决方案。
Serial Rapid I/O
另一种新生的串行标准是Serial Rapid I/O。和PCI Express一样,Serial Rapid I/O已植根于源同步领域。当与已有的Rapid I/O并行规范结合在一起后,Serial Rapid I/O能使设计者标准化一种用于网络、电信及其它嵌入式应用的单一互联技术。
Serial Rapid I/O是一种可升级的、点到点的、低引脚数的互联方式,它经设计后用于满足日益增长的系统带宽要求。Serial Rapid I/O 极大地影响了在光纤通道(Fibre Channel)、10G 以太网XAUI接口和Infiniband中的业界标准的信号技术。它以每个链路1.25, 2.5 和3.125 吉比特的速率工作,提供了信号处理器和背板应用所需的带宽。该串行规范定义了器件之间每个方向上的单个差分链路,并且支持将四个链路合在一起以取得更高吞吐量的应用。
如图2所示,Serial Rapid I/O也有一个分层的协议结构。莱迪思半导体公司也提供了一个器件系列,当外加嵌入式ASIC和软件IP核时,提供了一种低成本、低功耗和高度集成的解决方案。这种方案用于处理Serial Rapid I/O规范的物理层,并且在将来会支持逻辑层和传输层。
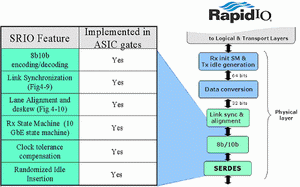
图 2 - Serial Rapid I/O协议栈的实现
与PCI Express类似,Serial Rapid I/O的实现也受益于可编程器件提供的固有的灵活性。在这里,可扩展的逻辑和传输层功能能够在FPGA中实现,而物理层的固定功能则在器件的ASIC部分中实现。
无线网络:CPRI和OBSAI
在无线领域,为了让蜂窝式基站更快地发展,当前有两种提案在角逐。CPRI和 OBSAI标准都面向串行传输协议的标准化,其首要的目的是通过元件的标准化来降低整个系统成本。
CPRI
CPRI(通用公共无线电接口)是一种业界的提案。它试图通过把基站分成两个基本构件来支持灵活的基站结构。这两个构件是:用于处理基频功能的无线电设备控制(REC)和提供射频(RF)功能的无线电设备(RE)。
构件通过一个经过8b10b编码的串行链路互连,试图利用已有的高速串行标准,诸如以太网和光纤通道。物理层的线速为614Mb、1.228Gb或者2.456Gbps,其通过单个串行接口被三种不同的信息流(用户平台数据、控制及管理、同步)多路复用。
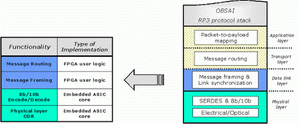
莱迪思半导体公司为CPRI应用提供了一个完整的解决方案。物理层功能通过嵌入在ORTx2G5器件中的ASIC核来支持,与之相关的软IP核处理数据链路层的功能,如图3所示。
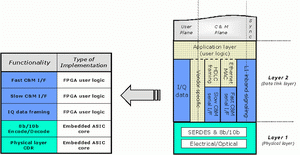
图 3 – CPRI协议栈的实现
OBSAI
类似的,OBSAI把基站分为基频和射频块,但是还定义了一个附加的传输和控制块。与CPRI相比,它们之间的每一接口都具有唯一的参考点,分别定义为RP1 (控制平台),RP2 (传输和基频块之间的用户平台)和RP3(基频和射频块之间的用户平台)。这些构件被指定为以太网接口,但出于本文的目的,我们将着重于RP3接口,因为它是一个8b/10b编码的串行链路,与上面提到的CPRI规范相类似。
由RP3接口支持的物理层线速为768Mb和1.536Gbps,支持高速数据传输及相关控制。该协议栈仍然是一个采用分层协议的信息包概念,如下面图4所示。
此外,莱迪思FPSC器件的SERDES和基于8b/10b的功能提供了一个支持完整的OBSAI系统解决方案的集成平台。物理层功能通过嵌入在FPSC器件中的ASIC核来支持,与之相关的软IP核处理数据链路层的功能。
系统互连构架
对电路板设计者而言,要达到上述新生串行标准所需的高传输速度是一项极大的挑战,尤其是在面临成本控制的时候。不同的行业有着不同的方法来平衡价格和性能,以及选择合适的连接器和传输媒体。
PC市场是一个成本驱动的行业,其中的连接器和电缆既非高速,又非高密度(可能的例外是高端服务器,当然其成本比一般的PC高得多)。要在这样一个竞争激烈的行业中控制整体成本,相互协作是关键。因此,大的OEM厂商联合起来并为一些应用建立规范,如PCI-Express, SATA, SAS, Fiber Channel, FireWire, DVI, HDMI及其类似的规范,不仅在协议层,而且在物理连接层。
在通讯基础结构行业,一些应用,诸如多重服务交换机、路由器及无线BTS等,标准化仅仅发生在协议层和用户至网络接口(UNI)中。更多的情况下,物理互连并不基于标准,并且通常是用户化的。
在很多情形下,机内互连(通常采用高速电缆实现)是用户化解决方案的典型例子,尽管它们可能在传送标准化的协议。
对于任何一种方法,其挑战是在不降低系统性能的前提下,尽可能提高成本效率。以下是经常遇到的问题:
- 如何在电路板间或板内利用随处可见而且经济的PCB/传输原料。
- 如何通过优化系统参数来设计最经济的结构。
- 在上述互连物体中选择具有最恰当尺寸的连接器,并且不影响系统运行目标。
根据这些问题,下面的讨论将突出当今市场上两种主要有线中枢的优缺点:什么是能改进整个系统性能性并能扩展其长度的最通用、最具成本效率的技术?
该讨论基于这样的事实:系统互连的最终结果是最具成本效率的,并且是可行的解决方案。
连接器、媒体类型和运行结果
连接器:
板间连接器细分为两组:开放式连接器和控制阻抗连接器。
对于开放式连接器,其单位长度上的性能和利用率直接由引脚分配和信号与地的比率所确定,例如:EuroCard-DIN,Z-Pack 2mm Hard Metric 或 FB+。
另一方面,控制阻抗连接器,诸如来自Tyco Electronics的2.5mm HS3和2.5mm HM-Zd,由于对于单端或差分类型的I/O信号的利用率为100%,所以它们不受此限制,并且对于给定的长度,能提供最高的密度。
由于控制阻抗连接器的抗扰度和吞吐量大大高于开放式连接器,设计者发现在保持充足的裕量和可接受的信道损耗的情况下,通过这些连接器传送极快的信号是很棒的。实际的问题是:系统性能的瓶颈不再是连接器本身,而是它在PCB中的引脚以及PCB的原材料。
背板/中间背板
PCB被非常普遍地用于系统内部中枢的元件互连。该领域已达到这样的水平:当采用诸如Tyco的HS3 或HM-Zd的高速/控制阻抗板到板连接器时,高成本效率的基于High-Tg FR4的PCB板能很好地在高达5吉比特的速度下工作。采用这种结构,系统互连可以达到这样的水平:基于PCB板互连的串行数据通过1270mm(~50”) 时以3.125Gbps的速度传送,或者通过762mm (~30”)时以5Gbps的速度传送。当然,这依赖于芯片的驱动特性以及芯片的接收灵敏度。
图5展示了一个由Tyco和莱迪思推出的演示系统。在这个系统中,FPGA多路传输并行数据,并且将它以每信道3.125Gbps的速率串行到几个信道中。它通过一个由HM-Zd 连接器和基于5mm厚的多层High-Tg FR组成系统互连的 876mm的无源信道(“底层”)来传送。
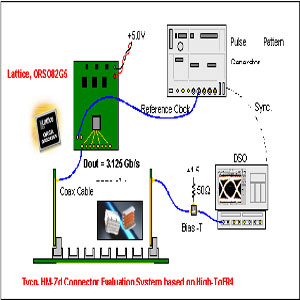
图5 – Tyco/莱迪思互连设置
莱迪思的ORSO82G5的“差分”输出电压是883mV(在3.125Gbps速率下),输出抖动是36ps(峰-峰)。图6展示了在接收器输入端测量到的“眼图”,驱动器分别设置为没有(左“眼”)和有(右“眼”)预加强。
402.7 mV Eye Opening 56.2 ps Total Jitter (Pk-Pk) 237.8 mV Eye Opening 121 ps Total Jitter (Pk-Pk)
“DSO” 与Bias-T一起作为接收器的输入端。通过将“DSO”与接收器的输入端并联,从而不影响系统阻抗连续性。
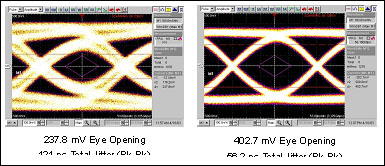
图 6:Tyco/莱迪思背板互连设置
这两个“眼图”是通过876mm (34.5”)长的、采用两个HM-Zd (高速及控制阻抗连接器)和莱迪思带有“SERDES”接口的FPGA系统互连测量到的,工作速率为3.125Gbps。
左侧的“眼图”代表了“平的”驱动器输出,并且清晰地指出即便当信号有相当大的抖动时,它仍然以相对于眼图波罩有充足的裕量在工作,从而恢复数据。当驱动器的输出设置为信号的25%预加强时,信号的传输品质(STQ)被极大地改善了,如右侧“眼图”所示。在触及接收器的最小敏感度之前,其信道长度高达1270mm(~50”)。
选用多层板内的哪一层来连接会极大地影响信道的长度。
结论是要取得最大和最具成本效率的系统互连成果,每个因素必须被视为总体装配的一部分,而非各自独立的。
高速电缆
对于许多串行高速应用的另一项挑战是满足比那些PCB更长的信道的需要。通过铜质媒介传输仍然是具有成本效率的,只要其长度小于20米。机柜内架子到架子以及机内应用是铜质电缆可以使用的一个实例。
以前,我们看到用优质的芯片和连接器组成的最佳信道在3.125Gbps速率下,可以达到1200mm,这是系统机柜内的有用的解决方案。数米内的机柜内架子到架子以及机内高速解决方案需要高速电缆。
因此,我们要将背板替换为电缆,并且当优化完信道后,检查整体性能。
在吉比特速度下,串行互连的数据率通常比并行互连快10至20倍,每个设计者都会遇到与信号传输品质(STQ)以及电磁兼容性有关的问题。
显然,短范围的系统内互连必须是具有成本效率的,还必须通过铜质电缆传送高数据率,而且可能是差分信号。
仔细检查电缆组件,可得出设计者必须牢记的几个关键因素:
· 电缆连接器在终止电缆时,必须保持合适的信号传输品质,以及符合电磁兼容性的要求,并且必须符合所有必需的机械特性,诸如不同的导线尺寸(AWG,美国线规)等,具有闭锁和调变性能等。
· 未经处理的电缆常常是最大的损耗和辐射噪音的来源。
· 与系统尺寸相比,电缆组件在物理和电器方面都是较长的。
· 电缆的特性(相偏、IL、RL、DC阻抗等)在整体运行中起关键作用
- 集肤效应 – 是指电流趋向于集中在导体的表面。集肤的深度随着频率的升高而变薄,并且直接与
- 直流和低频损耗 – 当频率升高导致导体的直径小于集肤深度,从而呈现有限的抵抗损耗时,就会发生这种情况。它直接与电缆长度成比例。
- 频散 – 是指由于随频率的升高,信号传播的速度变化而导致的信号幅度的损失。它直接与频率成比例。
- 介质损耗 – 是指由于信号的频散,尤其是在高频传输时的“饱和”的偶极子现象引起的介质材料的抵抗损耗。该现象使得当绝缘材料中的电场变化后,偶极子无法跟随变化。
- 不同的相偏 – 是指由两根导线组成的一对导线的不对称性能。不同的相偏会产生两个主要问题:由于上升时间的降低,”眼图”变坏了,以及共模电流可能对电磁兼容性产生负面影响。
· 串扰 – 通常以源电压的百分比来衡量,指的是能量从主动的信号耦合到被动的相邻信号,引发错误的数据来触发无源接收器。
· 符号间干扰(ISI)- 与数据类型直接相关,引起过零点的时间漂移(又称数据相关抖动 “DDJ”)。图7说明了ISI的结果。
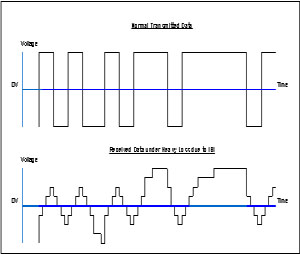
图7 – 符号间干扰(ISI)的图解
考虑到这些之后,如何为应用选择最佳的电缆和连接器?选择电缆连接器和电缆组件的标准是什么?如何改进电缆组件的性能以便最终拓展其长度?
在板至板连接器的情况下,当考虑电缆时,综合考虑整个系统结构以及芯片驱动器和接收器是至关重要的。这非常类似非标准应用解决方案(这种情况很多见)的情况。
电缆连接器
电缆连接器是和未加工电缆本身一样重要的一个部件。整个电缆组件必须紧凑并且易于装配,具有改进了的屏蔽作用,而且要便宜。
并非很多连接器都能满足这些标准,在质量和成本之间权衡是常见的事。
本文将讨论能满足上述标准的一种电缆连接器 -1mm Giga I/O,含有集成无源均衡的选择以及在单个连接器上提供10个高速的差分对。
未加工电缆
选择合适的未加工电缆是电缆组件的整体性能中的一个关键因素。现有的几种用于高速差分信号的电缆结构:
UTP – 无屏蔽的双绞线
STP – 带屏蔽的双绞线
SPP – 带屏蔽的平行线(也称为平的Twin-Ax)
差分信号天生与两种阻抗值相关:100Ω 的差分和150Ω的差分。100Ω的差分电缆在业界最常用,因为它的整体尺寸比150Ω的差分电缆要小,尽管100Ω的差分电缆会导致更高的频率损耗。
电缆的结构是根据传输距离来选择的。相对于SPP, STP有较大的相偏,因此对于长距离传输时会积累太大的相偏,会极大地影响插入损失。
另一方面,SPP电缆更为结实,并且用结实的导线做成,因此更难终止(连接器中的导线管理),不如STP灵活。
一个全双工的信道应用需要1X,4X,或12X电缆结构;按照定义,1X电缆在每个方向上有一个差分对,也称为一个串行/扭绞四芯电缆。通常,1X电缆用于“光纤通道”(150 Ω)和“InfiniBand”(100 Ω)中。
一根4X电缆在每个方向上有四个差分对(共计8捆SPP或者STP,全部在圆套内屏蔽),也称为4-扭绞四芯电缆。这种电缆适用于“XAUI”和“InfiniBand”应用,仍然被视为一个串行高速信道。
在同样情况下,一根12X电缆在有24捆SPP或者STP,称为12-扭绞四芯电缆。这种电缆适用于多路串行(如在PCI Express中)或者并行高速互连。
预增强
在发送端,预增强是这样一种技术:它用来解决恼人的抖动和在长距离、有损耗的信道接收端的眼图性能。
在驱动端的输出预增强/衰减信号的幅度意味着:
- 对输出的数字滤波采用基于历史输入的有限脉冲响应(FIR)滤波器或者基于历史输入和输出的无限脉冲响应(IIR)滤波器
- 放大较高的频率(连续位改造)来弥补电缆损耗
- 发送后尽最大可能驱动信号,并且在较低频率的情况下衰减信号(约衰减30%)- 连续位不变。
图8说明了如何在驱动端实施预增强,从而解决图7中所示的接收端符号间干扰(ISI)问题。
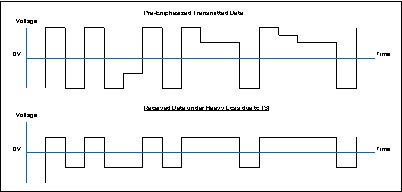
可以把均衡器植入芯片或者电缆组件中来补偿电缆产生的衰减和频散。如果输出信号不够大,或者如果用于有效信号恢复的数据相关抖动太大,那么采用一个无源均衡器来均衡基频,从字节率到位率来均衡频率(对于3.125Gbps ‘XAUI’ 或者 10GE系统,频率从156.25 MHz到1.5625 GHz)。
均衡器在频域范围内产生一个类似电缆相反传递函数的传递函数。合在一起,新产生的传递函数在电缆组件传输或者至少是基频的频率范围内工作相对平坦。
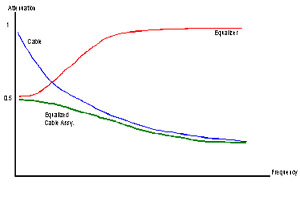
图9:未加工电缆、无源均衡器和经均衡后的电缆的典型频率响应
均衡器的通常类型是高通滤波器。由于均衡器的特性是要根据电缆组件的长度、未加工电缆的特性、数据率等进行特别地调整,因此Tyco的电缆连接器现在已经把它作为电缆组件的一部分集成了起来。这样还能在保持合理的阻抗性能的同时,实现均衡作用。
现在本文要考察一个实际的解决方案:它用铜质电缆组件作为整个系统互连的组成部分 – 芯片驱动器是莱迪思半导体公司的FPGA –,从而验证在基于高速数据率(诸如PCI Express、SRIO、 CPRI/OBSAI 或者用户化的背板应用)的各种网络应用中,该方案具有的灵活性。
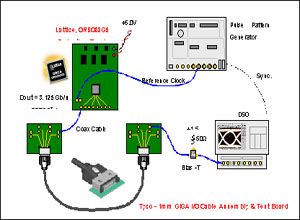
图 10:Tyco/Lattice电缆互连
图10展示了与上文提及的相同(基于PCB)的背板互连。但是为了拓展信道长度来阐明机柜内的解决方案,现在用电缆替代了FR-4背板。
所用的电缆连接器是Tyco的“1mm Giga I/O”。该连接器具有以下特性:
- 混合的电缆连接器(34个信号和4组电源连接)
- 细小的连接器波形系数,具有“按-锁”的金属扣
- 卡的边缘接触概念:
§ 可控制的阻抗
§ 灵活的电缆终止
§ 多种导线标准尺寸
§ 可通过插槽选用无源均衡器
- 良好的电磁兼容性
§ 低接地阻抗
§ 屏蔽功能
所用的电缆是MADISON的TurboTwin™ (P/N: 16KD200002),带有 8 x “SPP”类型,100Ω 差分,28AWG。
采用这样的连接器并结合预增强(Lattice FPGA输出)和无源均衡(Tyco的电缆连接器)手段,可以获得最长、最佳和最具成本效率的解决方案。
当不采用上述技术时(例如:既无在驱动端的预增强又无经均衡的电缆组件),通过8米长的电缆组件后,接收端的眼图将变成图11所示的波形。
|
| >
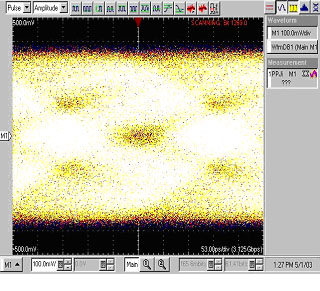
图11 – 未经优化的电缆互连结果
如果采用了预增强或者电缆均衡手段后,结果将大大改善。不过,图12中展示了在接收端测量到的眼图开度不足的情况。
| 25% Pre - emphasis only: | | Passive Equalizer only |
|
| >
| 40.54 mV Eye Opening @ 50% 209 ps. Total Jitter (Pk-Pk) | | 121.6 mV Eye Opening @ 50% 61.5 ps. Total Jitter (Pk-Pk) |
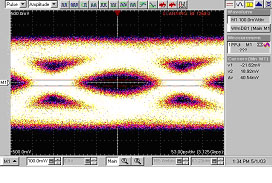
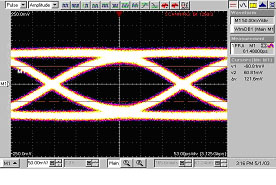
图12: Lattice和Tyco单独优化电缆互连的结果
由于要求最大的电缆长度,结合莱迪思SEDES驱动器输出的预增强和Tyco优化的(在电缆连接器中的嵌入式均衡器)电缆组件是最佳的解决方案,如图13所示。它使得电缆长度最大化,因此是最具成本效率的解决方案。
由于1mm Giga I/O电缆连接器能够适用8-10个高速差分对并且莱迪思的SERDES具有4个高速输出和4个高速输入,因此本文所探讨的系统互连组件构成了一个完整的PCI Express/SRIO x4信道或者其它的实现方式,如高达3.125Gbps的、具有成本效率的“XAUI”端口的解决方案。
降低数据率以满足CPRI/OBSAI的最大数据率(2.5Gbps),能够让设计者在拥有安全裕量的情况下将电缆延长到10米。
必须牢记单独地优化电缆和具有预增强和均衡器的综合解决方案是不同的。所以,必须把整个系统的元件作为一个整体来考虑。
|
| >
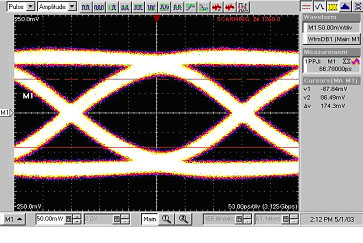
图13:用于优化电缆互连的Lattice / Tyco综合解决方案的结果
结语
随着通信和存储系统行业为了获取高带宽和低引脚数连接而向着多种基于信息包的串行I/O方向发展,系统厂商要求芯片和基础构架厂商提供给他们一步到位的解决方案,因为他们要把精力集中在提高整个系统的附加值上。
为达此目的,这些系统厂商的供应商必须提供具有强大信号完整性和灵活的芯片解决方案。争取业界标准基础构架的行动将变得越发迫切,因为厂商要努力地缩短上市时间,更为重要的是提高互用性。如上所述,这些标准化组织已经开始热情地工作了,如PCI-SIG和PICMG论坛。