简介
数字信号处理 (DSP) 是一种采用增强功能处理信号与数据,以及修改这些信号的方法。数字信号处理技术还可用于分析信号,以确定特定的信息内容。DSP 主要涉及真实信号的处理。这些信号根据序号进行转换与表示。然后采用数学方法处理这些信号,以便从信号提取特定信息或者以某种方式转换信号。
DSP 一般驻留在实时嵌入式系统,其中计算的及时性与其正确性同等重要。DSP 在这些环境中很普通,因为对它们经过精心设计后,可非常迅速地执行常见的信号处理运算。DSP 的可编程性使应用能够随时间而改变和演进,从而为应用供应商提供众多优势。对 DSP 编程需要了解应用、DSP 硬件架构、以及用于生成可满足系统紧迫期限要求的高效实时软件代码生成工具。
本文是系列文章的第二部分,总结在实践中从高性能 DSP 获得数量级速度提高所采用的某些技术。
优化的首要原则----切勿盲动!
在开始进行任何优化之前,您必须了解从何处着手。就性能方面来看,并非所有软件生来相同!您必须首先了解瓶颈在何处。一旦分析了应用,就可以开始调整代码。应用程序分析意味着权衡需在每部分代码所花费的时间(或者所占用的内存、所消耗的功率)。软件的某些部分可能只执行一次(初始化)或者只执行少数几次。如果费尽心思优化此部分代码并非明智之举,因为获得的整体节省效果会是微乎其微。更可能的情况是,会有几部分软件执行很多次,尽管代码自身可能会很短,但代码执行频繁意味着花费在该代码的总循环会很多。即使如果您在这些代码中可以节省一、两个循环,所获得的节省也会很可观。这就是在调整和优化过程中您应该多费些时间的地方。
并行是关键所在
在编程超量标及 VLIM 期间时所要遵循的标准原则是"保持流水线充满"(Keep the pipelines full!)。充满的流水线意味着有效的代码。为了确定流水线充满的程度,您需要费些时间检查汇编程序生成的汇编语言代码。通常可以根据代码中NOP 的冗余性检查低效的代码。
为了证明在基于 VLIW 的超量标机器中并行性的优势,让我们首先从图 1 所示的简单循环程序入手。如果我们准备编写此程序的串行汇编语言实施,其代码会与图 2 中的类似。此循环采用超量标机器的两个可用侧之一。通过指令与 NOP 计数,它需要 26 个循环来执行循环的每个迭代。但是,我们可以做得更好。
在这个例子中,需要注意两件事情。许多执行单元并未使用,而是处于空闲状态。这是对处理器硬件的浪费。其次,在汇编程序的此部分存在众多延迟间隙(准确说是 20 个),在其中 CPU 需要停滞下来等待加载或保存数据。在 CPU 停滞时,不会进行任何操作。在试图处理大量数据时,这对处理器是很糟糕的事情。
有众多方法可以在等待数据期间保持 CPU 运转。我们可以执行不依赖正在等待的数据的其他运算。我们还可以使用超量标结构的两侧来帮助加载和保存其他数据值。图 3 中的代码就是一种对串行版本的改进。我们已经将 NOP 的数量从 20 个降至了 5 个。我们还可以并行执行某些步骤。第 4 行和第 5 行同时执行向器件的两个单元(D1 和 D2)的加载。此代码还执行循环前的分支运算,然后充分利用与该运算相关的延迟来完成当前循环的运算。请注意,在该代码中存在新的一列,它可指定您希望将哪次执行单元用于特定运算。这种指定执行单元的灵活性使您能够更好地对运算进行控制。
1 void example1(float *out, float *input1, float *input2)
2 {
3 int i;
4
5 for(i = 0; i < 100; i++)
6 {
7 out[i] = input1[i] * input2[i];
8 }
9 }
图1:简单的C循环
1 ;
2 ; serial implementation of loop (26 cycles per iteration)
3 ;
4 L1: LDW *B++,B5 ;load B[i] into B5
5 NOP 4 ; wait for load to complete
6
7 LDW *A++,A4 ; load A[i] into A4
8 NOP 4 ; wait for load to complete
9
10 MPYSP B5,A4,A4 ; A4 = A4 * B5
11 NOP 3 ; wait for mult to complete
12
13 STW A4,*C++ ; store A4 in C[i]
14 NOP 4 ; wait got store to complete
15
16 SUB i,1,i ; decrement i
17 [i] B L1 ; if i != 0, goto L1
18 NOP 5 ; delay for branch
图2:C循环的串行汇编语言实施
1 ; using delay slots and duplicate execution units of the device
2 ; 10 cycles per iteration
3
4 L1: LDW .D2 *B++,B5 ;load B[i] into B5
5 LDW .D1 *A++,A4 ;load A[i] into A4
6
7 NOP 2 ; wait load to complete
8 SUB .L2 i,1,i ;decrement i
9 [i] B .S1 L1 ; if i != 0, goto L1
10
11 MPYSP .M1X B5,A4,A4 ; A4 = A4 * B5
12 NOP 3 ; wait mpy to complete
13
14 STW .D1 A4,*C++ ;store A4 into C[i]
图3:C循环更具并行性的实施
循环展开
循环展开是一种用于提高在循环分支逻辑之间执行的、指令数量的技术。它可以降低执行循环分支逻辑的次数。由于循环分支逻辑是额外开销,降低其次数可以减少开销,而且可以使循环主体-结构的重要部分运行更快。通过复制循环主体一定次数、然后修改终端逻辑来理解循环主体的多个迭代,可以展开一个循环。循环展开的缺点是使用更多的片上寄存器。每个迭代需要使用不同的寄存器。一旦使用了可用的寄存器,处理器就会开始访问堆栈保存所需要的数据。访问片外堆栈需要很高的代价,并且有可能消除由展开循环而实现的增益。只有在循环的单个迭代循环展开中的运算没有使用处理器结构的全部可用资源时,才可以使用循环展开。如果您对此不很确定,请检查汇编语言输出。另一个缺点是增加代码长度。展开后的循环需要更多指令,进而需要更多内存。
软件流水线化
最佳优化策略之一是编写能够由汇编程序有效流水线化的代码。软件流水线化是一种有效调度循环和功能单元的优化策略。比如在 TMS320C62x™ 生成中,如果汇编程序了解如何操作,则存在 8 个可以同时使用的功能单元。有时只是 C 代码结构的细微更改,其就有可能产生大为不同的结果。在软件流水线化中,会调度循环的多个迭代来并行执行。循环会被重新组织,其结果是流水线化后的代码中的每个迭代都是由从原始循环中不同迭代选择的指令序列构成。在图 4 所示的例子中说明了一个带 3 个迭代的 5 步骤循环。在管线被 "primed" 或者最初加载运算时,存在一个称为 prolog 的初始阶段(循环 n 与 n+1)。循环 n+2~n+4 是实际流水线化后的代码部分。处理器就是在此部分中针对三个不同循环(1、2、3)执行不同运算(C、B、A)。这里存在一个 epilog 部分,其中,退出循环之前执行剩余的指令。只是一套充分利用的流水线,其可生成速度最快、效率最高的代码。
如图 5 所示,软件流水线化比循环展开速度更快,因为尽管建立流水线的开销更为复杂,但是只执行一次,而在展开的循环中却要执行多次,在标准循环建立过程中会执行许多次。
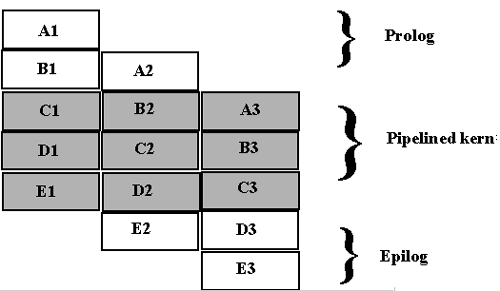
图 4:软件管道化的五步骤管道
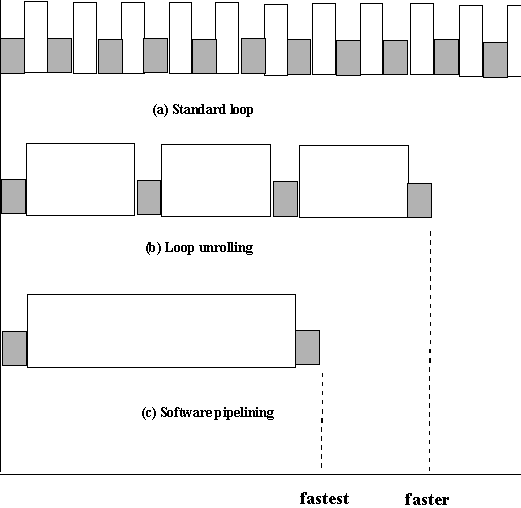
图 5:标准循环开销与循环展开及软件流水线化的对比
图 6 说明同样简单的部分 C 代码以及相应的汇编语言输出。在此例中,要求汇编程序尝试流水线化代码。汇编语言输出中的流水线化后的循环 prolog 和循环核心部分就是证明。在这个例子中,流水线化的代码并未达到其最佳效果。您可以通过查看代码流水线化后的循环核心中存在多少 NOP 来检查低效的代码。此例中,流水线化后的循环核心总共有 5 个 NOP 循环,第 16 行中 2 个,第 20 行中 3 个。此循环共需要执行 10 个循环。NOP 是能够实现更有效循环的首要证据。但是,这个循环到底能够有多短呢?预计最小循环长度的一个方法是确定哪个执行单元使用次数最多。在该例中,单元 D 比其他任何单元使用得都更频繁,总共使用 3 次(第14、15 与 21 行)。超量标器件存在两侧,从而在最低 2 个时钟的循环中每个时钟可以使用每个单元两次(D1 和 D2),即一个时钟 2 次 D 运算,第二个时钟中 1 个 D 单元。汇编程序具有足够的智能在流水线的两侧使用 D 单元(第 14 行
和第 15 行),从而使它能够并行化指令并且只使用 1 个时钟。在等待完成加载的同时可以执行其他指令,而不是坐等 NOP 延迟浪费时间。1 void example1(float *out, float *input1, float *input2)
2 {
3 int i;
4
5 for(i = 0; i < 100; i++)
6 {
7 out[i] = input1[i] * input2[i];
8 }
9 }
1 _example1:
2 ;** ---------------------------------------------------------*
3 MVK .S2 0x64,B0
4
5 MVC .S2 CSR,B6
6 MV .L1X B4,A3
7 MV .L2X A6,B5
8 AND .L1X -2,B6,A0
9 MVC .S2X A0,CSR
10 ;** ---------------------------------------------------------*
11 L11: ; PIPED LOOP PROLOG
12 ;** ---------------------------------------------------------*
13 L12: ; PIPED LOOP KERNEL
14 LDW .D2 *B5++,B4 ;
15 LDW .D1 *A3++,A0 ;
16 NOP 2
17 [ B0] SUB .L2 B0,1,B0 ;
18 [ B0] B .S2 L12 ;
19 MPYSP .M1X B4,A0,A0 ;
20 NOP 3
21 STW .D1 A0,*A4++ ;
22 ;** --------------------------------------------------------*
23 MVC .S2 B6,CSR
24 B .S2 B3
25 NOP 5
26 ; BRANCH OCCURS
图 6:C 语言例子以及相应流水线化的汇编语言输出
在循环的简例中,很明显输入独立于输出。换句话说,并不存在相关性。但是,汇编程序对这点一无所知。汇编程序一般来说是有点悲观的小家伙。在形势不明朗的情况下,它一般并不进行任何优化。汇编语言比较保守,会假定输入每次通过循环时会依赖此前的输出。如果了解了输入与输出无关,我们就可以通过把 input1 和input2 断言为 "const" 来提示汇编程序,向它说明这些字段不会改变。这是进行软件流水线化和节省吞吐量的切入点。图 7 说明了这种 C 代码及其相应汇编语言。
1 void example2(float *out, const float *input1, const float *input2)
2 {
3 int i;
4
5 for(i = 0; i < 100; i++)
6 {
7 out[i] = input1[i] * input2[i];
8 }
9 }
1 _example2:
2 ;** ---------------------------------------------------------------*
3 MVK .S2 0x64,B0
4
5 MVC .S2 CSR,B6
6 MV .L1X B4,A3
7 MV .L2X A6,B5
8
9 AND .L1X -2,B6,A0
10
11 MVC .S2X A0,CSR
12 SUB .L2 B0,4,B0
13
14 ;** --------------------------------------------------------------*
15 L8: ; PIPED LOOP PROLOG
16
17 LDW .D2 *B5++,B4 ;
18 LDW .D1 *A3++,A0 ;
19
20 NOP 1
21
22 LDW .D2 *B5++,B4 ;@
23 LDW .D1 *A3++,A0 ;@
24
25 [ B0] SUB .L2 B0,1,B0 ;
26
27 [ B0] B .S2 L9 ;
28 LDW .D2 *B5++,B4 ;@@
29 LDW .D1 *A3++,A0 ;@@
30
31 MPYSP .M1X B4,A0,A5 ;
32 [ B0] SUB .L2 B0,1,B0 ;@
33
34 [ B0] B .S2 L9 ;@
35 LDW .D2 *B5++,B4 ;@@@
36 LDW .D1 *A3++,A0 ;@@@
37
38 MPYSP .M1X B4,A0,A5 ;@
39 [ B0] SUB .L2 B0,1,B0 ;@@
40
41 ;** --------------------------------------------------------------*
42 L9: ; PIPED LOOP KERNEL
43
44 [ B0] B .S2 L9 ;@@
45 LDW .D2 *B5++,B4 ;@@@@
46 LDW .D1 *A3++,A0 ;@@@@
47
48 STW .D1 A5,*A4++ ;
49 MPYSP .M1X B4,A0,A5 ;@@
50 [ B0] SUB .L2 B0,1,B0 ;@@@
51
52 ;** --------------------------------------------------------------*
53 L10: ; PIPED LOOP EPILOG
54 NOP 1
55
56 STW .D1 A5,*A4++ ;@
57 MPYSP .M1X B4,A0,A5 ;@@@
58
59 NOP 1
60
61 STW .D1 A5,*A4++ ;@@
62 MPYSP .M1X B4,A0,A5 ;@@@@
64 NOP 1
65 STW .D1 A5,*A4++ ;@@@
66 NOP 1
67 STW .D1 A5,*A4++ ;@@@@
68 ;** --------------------------------------------------------------*
69 MVC .S2 B6,CSR
70 B .S2 B3
71 NOP 5
72 ; BRANCH OCCURS
图 7:相应流水线化后的汇编语言输出
在查看此汇编语言时需要留意几点。首先,流水线化后的循环核心已经缩小了。事实上,现在循环只有 2 个循环长。第 44-47 行在循环的第一个循环执行(并行指令由 符号表示),第 48-50 行在第二个循环执行。利用我们通过 "const" 断言提供的附加相关性信息,汇编程序已经能够充分利用这些单元中的并行优势来高效地调用循环的内部部分。但是,这点需要一定代价。代码的 prolog 和 epilog 部分现在已经变得大得多了。更紧密的流水线化核心将需要更多启动 (priming) 运算来根据各种指令和分支延迟协调所有的执行。但是,一旦启动 (primed),核心循环就能够以极其快的速度运行,在循环的各个迭代上执行运算。正如我们在前面所说明,软件流水线化的目标是提高经常性事件速度。 核心在此例中就是经常性事件,而且我们已经大大提高了它的速度。对于循环计数比较小的循环,可能不值得进行代码流水线化。但是,对于那些要执行数千次的循环计数较大的循环来说,软件流水线化是唯一的出路。
在流水线化后的核心要执行的 2 个循环中,会有许多事情发生。在汇编语言列表中的右列说明每条指令执行哪个迭代。每个 "@" 符号表示迭代计数。因此,在这个核心中,第 44 行为迭代 n+2 执行分支,第 45 和 46 行为迭代 n+4 执行加载,第 48 行保存迭代的结果,第 49 行为迭代 n+2 执行乘法,而第 50 行为迭代 n+3 执行减法,这一切全在 2 个循环中完成。一旦流水线化后的核心停止执行,epilog 就会完成运算。汇编程序能够使该循环变成 2 个循环长,这正是我们通过检查低效代码版本所期望达到的结果。
流水线化的功能的代码长度有所增加,看看所生成的代码就一目了然。这是编程人员为了追求速度而不得不面对的折中之一。
在使用堆栈的程序中,还存在必须要解决的其他问题。汇编程序必须确定在堆栈(需要更多时间访问)中放置哪些变量以及要在快速片上寄存器中放置哪些变量。汇编程序有时并不能确定变量的去处。它会干脆不费神地尝试去流水线化包含太多变量的循环。这种情况下,明智的做法是将大循环分成较小的循环,并使汇编程序能够对之进行流水线化(图 8)。
我们可以不采用:
for (expression)
{
Do A
Do B
Do C
Do D
}
而是采用:
for (expression)
Do A
for (expression)
Do B
for (expression)
Do C
for (expression)
Do D
图 8:将大循环分成较小的循环能够更有效地进行流水线化
如果不仔细分析并结构化代码,就不存在所谓的软件流水线化。例如,不要流水线化没有足够处理功能的循环。另一方面,也不能流水线化具有太多处理功能的循环,因为循环主体会耗尽可用的寄存器。此外,不能流水线化循环内的函数调用。相反,如果您希望获得流水线化后的循环,需要利用函数的内联扩展来代替函数调用。
流水线化的缺陷之一是禁用中断。完全 primed 管道中间的中断会破坏指令执行中的协同配合 (synergy)。汇编程序会在进入流水线化的部分之前禁用中断来保护软件流水线化运算,并在退出时启用中断(图 9)。这意味着获得软件流水线化效率的代价是不可抢先的代码部分。编程人员必须能够确定不可抢先代码的部分对现实性能的影响。
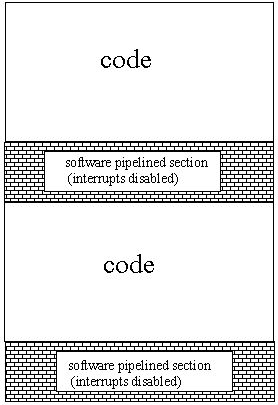
图 9:在代码的软件流水线化期间禁用的中断
最后手段――汇编语言
经常可以通过稍微修改 C 语言代码来缓解这种状况,但是获得最佳(或接近最佳)解决方案需要时间和多个迭代。图 10 说明了采用这种方法优化代码的过程。最后的方法是采用汇编语言对算法进行编码。汇编语言难以编写、理解和维护。正在开发相关工具使汇编语言编程人员更易于为超量标与 VLIW 处理器编写有效的代码。例如,汇编语言优化器就能使编程人员编写串行汇编语言,然后自动将其优化到软件流水线化后的循环中。
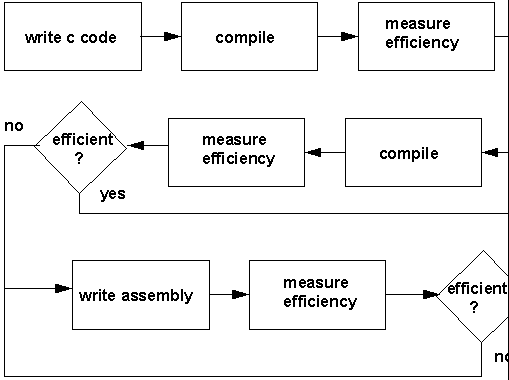
图 10:代码优化过程
结论
现实的编程人员经常不得不开发技巧库,以便使软件能够尽可能快地运行。随着处理器不断复杂化,这点正变得越来越困难。对于超量标 VLIW 处理器而言,需要工具支持来管理两个独立的流水线并确保最高的并行性。汇编程序的优化可帮助克服这些强大的新型处理器所带来的诸多难题,但是,汇编程序自身也有其局限性。现实的编程人员不应依赖汇编程序执行所有必要的优化。他们需要帮助!要遵循的步骤如下:
研究由汇编程序生成的汇编语言。许多情况下,稍微改变 C 代码结构可以大大改变汇编程序生成 .asm 语言的方式。这可以改变系统的现实性能。
使用 DMA 功能。尤其是对于 DSP 系统中数据密集型处理应用。DMA 可以大大减轻 CPU 的负担并帮助有效管理数据。
; 保持流水线充满。超量标与 VLIW 处理器发明的全部初衷就是要充分利用并行性的优势。检查汇编语言中的低效部分,并进行相应修改,以便以最高的效率使用两个流水线。这需要了解汇编程序在流水线化方面需要哪些东西。它还需要对应用有所了解。许多时候只需重新调整算法就能够使其在处理器上更有效地运行。
参考文献:
《TMS320C62X 编程者指南》,德州仪器,1997 年;
《计算机架构:量化方法》,作者 John L Hennesey 与 David A Patterson,加州帕拉托 Morgan Kaufmann 出版社 ©1990 版权所有。