AMD的第8代处理器-Opteron和Athlon 64进入我们视野已经有一段时间,对其相关介绍和评测也有不少,本文从K8的全新架构来深入了解一下AMD 64处理器以及其性能优势。
测试环境
Opteron平台
| 处理器 | 2 x Opteron 240 处理器 (1400MHz) |
| | 2 x Athlon 64 processors (1400MHz ,1600MHz,2000MHz) |
| 主板 | Rioworks HDAMA (AMD8131 + AMD8111) |
| | Soltek K8AV-R (VIA K8M400,Athlon主板) |
| | Asus SK8N (nForce 3 Pro,Opteron主板) |
| 内存 | Transcend 512MB DDR333(ECC纠错) |
Pentium 4平台
| 处理器 | Pentium 4 3.0 GHz(15 x 200),Pentium 4 3.2GHz (16x200) |
| 主板 | Asus P4C800(i875P) |
| 内存 | TwinMos DDR400 (2 x 256MB, 2-2-2-5) |
测试目的
1.了解Opteron处理器和Athlon 64处理器之间的性能差异。
2.了解K8架构的超频性能,在测试中,我们通过不断增加处理器的时钟频率,测试K8的超频性能。
3.K8架构处理器和P4处理器之间的性能比较。在具体测试之前,我们先来了解一下全新的AMD K8架构。
Opteron系列
AMD在今年的4月22日正式发布了Opteron处理器,令人最感兴趣的是,此次AMD并没有把时钟频率作为划分Opteron家族的标准,而是从多处理器的角度,把Operton处理器家族分成1XX,2XX和8XX三大类,它们分别针对单处理器系统,双处理器系统和8处理器系统。XX代表了每一系列的处理器的时钟频率标准,例如在2XX系列中,Opteron 240,242和244处理器的频率分别为1400MHz,1600MHz和1800MHz。在今年的8月4日,AMD又发布了代号为Opteron 246(2GHz)的处理器。同样,代号为146和846的Opteron处理器也已经上市。Opteron处理器均有128位内存接口,3条Hyper Transport总线和1024Kb的二级缓存。目前的Operton处理器只支持DDR266和DDR333的内存。Athlon 64处理器可以支持DDR 400内存。 Cache子系统 Cache系统性能的优劣直接影响到处理器的性能。在微机的整个架构中,Cache是处理器和内存系统之间的桥梁,所以它常常成为系统的首要瓶颈。和现有的K8相比,原先K7系统的缓存设计多少还不是非常完美。缓存的性能主要依靠“延迟”,“吞吐量”和其他一些指标来衡量,在K7的架构上(以Athlon XP为代表),K8的缓存系统又做了进一步的改进。
下图就是两者的对比。
| CPU | 一级缓存延时(L1) | 二级缓存延时(L2)最短 | 二级缓存延时(L2)最长 |
| Athlon XP | 3时钟周期 | 11时钟周期 | 20时钟周期 |
| K8 | 3时钟周期 | 11时钟周期 | 16时钟周期 |
在CPU读取数据的过程中,首先会在1级缓存中查找,如果1级缓存中存在所需的数据,那么读取过程完毕,这个步骤要花3个CPU时间,因此1级缓存的延时为3个时钟周期。
如果1级缓存中没有所需的数据,那么就要从2级缓存中调入所需的数据;这个过程又分为两种情况:如果1级缓存有空闲的空间,那么数据可以直接从二级缓存调入,这个过程会花费8个CPU时间,因此2级缓存的最短延时是3+8=11个时钟周期;但是,在通常大部分情况下,1级缓存并没有空闲的空间,那么按照一定的替换算法,系统会把1级缓存中的64字节进行转移,留出一定的空间,因为K7的总线宽度为64位,因此所花费的时间是8个时钟周期(64字节×8/64位=8),最后二级缓存还要1个时钟周期进行数据同步等操作,因此在最坏的情况下二级缓存的延时为3+8+8+1=20时钟周期。
和K7对比之下,K8的缓存是128位的宽度,因此在数据转移的过程中,就要比K7架构少4个时钟周期(64×8/128=4),从而二级缓存最坏情况延时为16时钟周期。根据不同的设置,K8也可以工作在64位总线宽度的模式下,那样的话,它的二级缓存延时就和K7完全相同。在真实环境中,由于CPU经常进行数据处理,因此1级缓存通常是饱和的,所以缓存系统大部分的时间工作在最坏情况下。
解码器和流水线
由于是64位的架构,因此K8架构中的x86指令解码器受到业界较多的关注。它和P4,K7的x86指令解码器均不同,做了较大的改进。 解码器设计的目标就是使得系统获得最大的性能;为了上层的架构,解码器还要考虑到指令功能的完备性,但是指令的完备性会在某种程度上降低系统的性能,因此在解码器设计时,就要考虑到性能和功能两大因素。同时,由于x86指令长度的不规则(最长有15字节),更给设计者带来了困难。
AMD和Intel为了提高系统的性能,采用了两种完全不同的方法。Intel通过提高CPU的时钟频率来提高性能,而AMD采用增加每时钟周期处理的指令数量来提高性能。首先我们先来了解一下P4和K7解码器之间的差别,然后讨论K7和K8之间的差别。
对于P4架构而言,它的出发点在于把无规则的x86指令转化成有规则的微指令操作,根据指令的复杂程度,相应的转化成1~3个微操作步骤(或者更多步骤)。由于规则的微指令操作,因此可以方便的通过叠带流水线来提高指令处理的效率。流水线的处理过程中,即将执行的指令会提前存储到Trace Cache单元。因此流水线越长,CPU的时钟频率越便于提高,这也是Intel CPU时钟频率持续快速提高的主要原因。但是过长的流水线,会给“分支预测”指令带来较大的开销,在分支预测错误的情况下,系统的性能会有所降低。
K7架构中,x86的指令主要有I-cache(指令缓存)来完成,它也是把X86指令转化成内部的微操作来提高系统性能,不过它实现的方法和P4略有不同。K7(K8)首先会对需要执行的X86指令进行分析和选择,然后把它的信息存储到一个特殊的“位阵列”(解码阵列)中,每一条指令在“位阵列”中占3比特的大小,处理器通过3比特的信息加速指令的处理过程,相同的指令只存储一次。
Intel P4和AMD K7(K8)对比而言,两者的相同点都是把X86指令转化成内部的微操作来执行。只不过前者Trace Cache单元存储转化后的微操作步骤,而后者I-cache存储指令的有用信息,减少重复的过程。 AMD K7(K8)最后根据存储的信息把X86指令再转化成“宏操作”,一般一条X86指令对应1~2条“宏操作”;其中最复杂的集合图形变化的X86指令对应的“宏操作”数量高达10条。由于每条“宏操作”长度和结构统一,并且每条通道可以同时处理2条指令,因此大大提高了系统的处理效率和性能。AMD K7/K8系统有3个同步通道,每个通道有独立的队列单元,因此可以同时处理6条指令。AMD把同时可以处理的指令数,即宏操作数称作“line”,整个流水线的操作都是以“line”为单元。AMD把这种技术称作“line-oriented”。
解码步骤:K7 VS K8 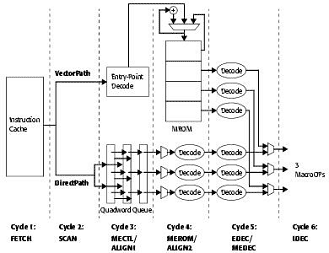
K8在K7的解码的前6个步骤上做了较大的改进,在K7的架构中,解码的前6个步骤分别为:
FETCH:取指,从I-cache中读入一个数据块。
SCAN:扫描,在“位阵列”信息的协助下,分离指令,分别发送到DirectPath单元或者Direct Vector和Microcode Engine单元。
ALIGN1:对齐。在缓存中填充来自于三个通道的指令。
ALIGN2:对齐。对三个通道的指令进行分析,完成指令预处理功能,并且生成“宏操作”。
EDEC:完成解码的过程。
IDEC:读入生成的“宏操作”,并为下次读取做准备。
7~15步骤略。
针对K7的步骤,K8做了相应改进,调整为8个步骤。
FETCH1 (和K7相同)
FETCH2
PICK
DECODE1
DECODE2
PACK
PACK/DECODE
DISPATCH(对应K7的IDEC )
2~7步操作和K7完成的功能基本相同,不过做了改进。K7的Direct Path(DP)和Vector Path(VP)在K8中合并成了一个统一的Direct Path Double(DD)单元。因此原先的SCAN过程大大简化,无需分离相应的指令。改进后,DD单元解码的速度比DP和DV提高了1.5倍。同时DD指令包括POP ,RET等寄存器指令,SSE,SSE2指令,因此在128位的SIMD指令的处理上,效率有了很大的提升。在K7的DP指令序列中,ALIGN1和ALIGN2的算法效率并不能达到100%(平均在80%~90%),而在DD指令序列中,尽管处理某些长指令的之间增加,但是整体上的效率有了很大的提升。
内存控制器
集成的内存控制器是K8的一个特点。但是在实际情况中,K8的内存控制器是否能够如所述的那样,有效的降低内存延时,并且提高内存的工作效率呢?
通过Cache Burst 32测试工具,我们来看看Athlon 64和Opteron的内存系统的表现。
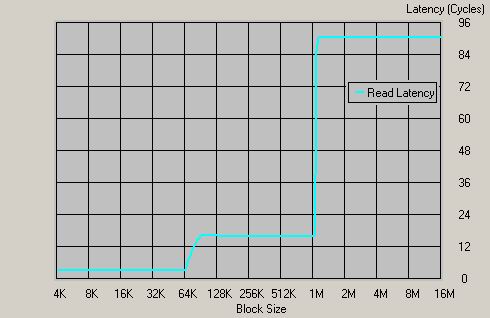
Athlon 64 1400MHz,DDR266
图中的内存延时为90个时钟周期,在1400MHz的时钟频率下,内存延时为64ns(90/1400=0.064),这个结果十分惊人,它的低延时可以和目前任何内存控制器相比,更何况它只是使用了快过时的DDR266内存。
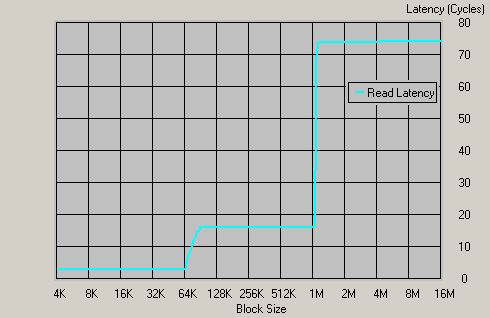
Athlon 64 1400MHz,DDR333
在DDR333的内存下,延时只有74个时钟周期(约为53ns),这足足可见集成的内存控制器的效率。
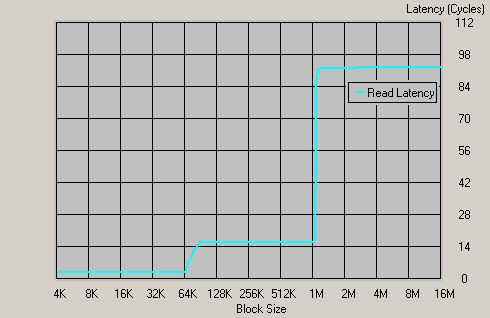
Opteron 1400MHz,DDR333(ECC)
我们也在带ECC纠错的DDR 333内存下进行测试,ECC 内存除了正常的数据存储和传输之外,还对数据进行纠错,因此它的工作速度要低于普通的内存模块。测试中,和普通的DDR 333相比,它的延时有所上升,约为94个时钟周期(约67ns),比普通DDR333增加了20%。不过这个得分已经相当不错了。
尽管DDR400还未通过JEDEC,我们还是进行了测试:
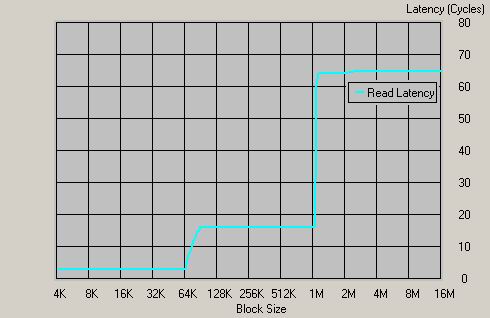
Athlon 64 1400MHz,DDR400
延时只有65 个时钟周期(46ns)!!!这个延时对于内存控制器而言,已经是非常出色了,无论web服务器,还是数据库都能从K8的架构中大大获益。在目前,以及今后一段时间内, AMD的内存控制器几乎没有竞争的对手。下文是P4+i875P+双通道DDR400的测试结果,这可是目前P4平台最好的内存系统。
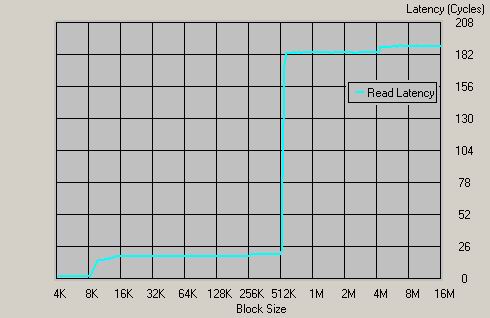
Pentium 4 3.0GHz, i875P + Dual DDR400
P4架构的内存延时高达189个时钟周期,因为P4本身的频率较高,因此,延时为63ns,和K8集成的内存控制器相比,P4系统顿时失色不少。
接着我们又对内存带宽进行测试,P4平台使用双通道的DDR内存,而AMD平台,分别针对Athlon 64 1400MHz和1600MHz测试。
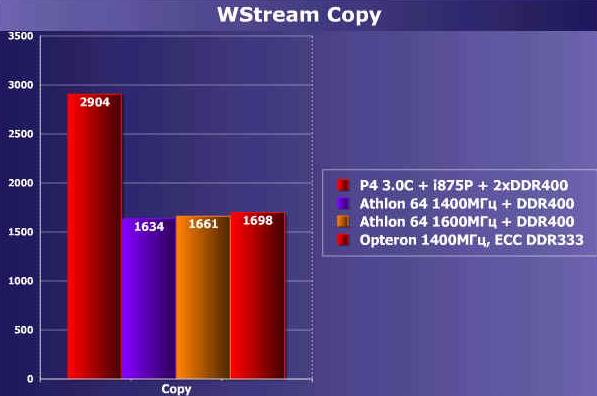
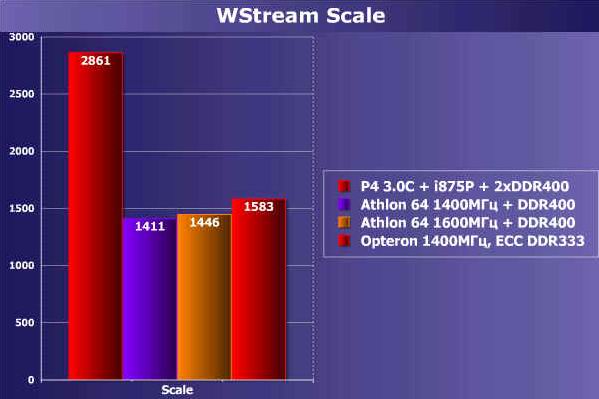
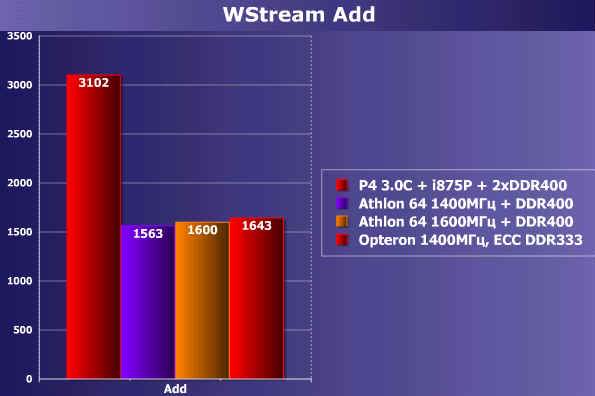
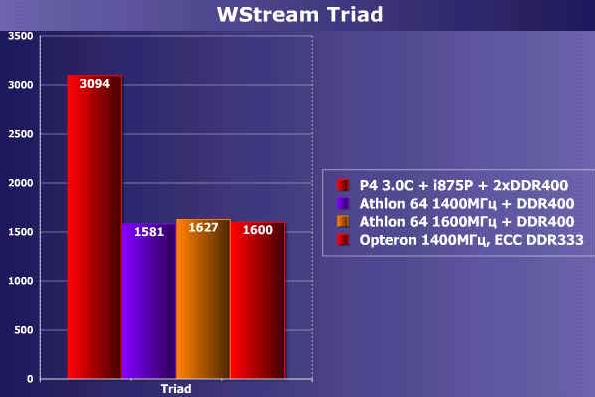
由于Intel P4使用的是双通道内存架构,而Athlon 64只是单通道内存的架构,因此内存的峰值带宽落后于P4。但是我们也可以注意,随着时钟频率的提高,Athlon 64的带宽随着CPU的频率的提高而提高。
总结
K8架构是AMD今年推出的拳头产品,尽管上市的日期一拖再拖,但是它的表现的确令人惊讶。Opteron和Athlon 64现在的主流频率只有1600MHz左右,但是它独有的架构使得内存延时性能大大领先于高端的P4平台。如果K8处理器的时钟频率再能提高的话,那么缓存的低延时会达到一个又一个的极限,这无疑对工作站和服务器是一个福音。
在测试中,同一架构下的Opteron和Athlon 64表现的性能几乎完全相同。由于针对不同的市场,服务器市场的Opteron主要强调可靠性,会以一部分性能来换取数据的稳定和可靠,在实际的应用中通常搭配带ECC校验的DDR333内存;而针对工作站和主流市场的Athlon 64强调高效性,它的主要竞争对手就是现有的P4平台。AMD官方消息,2.2GHz的Athlon 64在10月初会上市,根据此次的2GHz的Athlon 64表现,我们绝对可以认定,2.2GHz的Athlon 64系统性能会超过3.2GHz的P4处理器。
在最终的对比测试中,Athlon 64尽管在多媒体编码上性能不佳,但是在其他测试中,性能绝对可以和P4平台进行抗衡。P4平台也做的十分不错,Intel依靠不断提升的时钟频率来增强系统的绝对优势,i875P芯片组和双通道DDR内存帮助下,Intel在内存带宽上有着绝对的优势,其综合实力也强于AMD。面对AMD的不断出击,Intel绝对不会坐以待毙,即将出路的Prescott会是K8的强力反击。
