将集中式体系结构重新分配,使包处理分布到单个的线卡上,这为未来的需求奠定了基础
---- 在过去的几年中,全球的通信基本设施经历了空前的增长和彻底的变化。除每月数以百万的新用户联机以外,互联网应用程序变得日益直观化,这些应用程序需要更多的带宽。 ---- 数据、声音和视频服务集中在相同的基础设施上,这也驱动了将不同的服务质量水平(QoS)一体化和对其进行管理的需求。QoS管理是必要的,它可以保证对等待敏感的优先通信量作出响应。 ---- 以电缆调制解调器和DDL形式出现的宽带连接也极大地拓宽了网络管线的"延续里程",给予用户更快的访问和使用带宽密集内容的更大倾向性。向宽带的转变驱使大区域(metro-area)服务提供商终止数百万条新的宽带线路,处理位于网络边缘的不断攀升的通信量。 新型体系结构 ---- 朝向网络核心的高速光纤连接(如oc-48和oc-192)与密集波分复用(DWDM),正在显著地增加可用连接的数目以及每个连接的传播速度。这些新需求和性能正驱动一次整个因特网所使用的基础路由和交换体系结构的广泛再设计。 ---- 这些新交换和路由体系结构的关键要求包括以下内容: ---- 目前新一代路由器中出现的基础体系结构的改变之一是:智能由交换结构向单个线卡大规模的转变。由于路由器从本质上提供了在网络和子网中无缝运载通信量的神经元,这些关键的体系结构改变可能显著提高整个基础结构性能。 ---- 向更加智能化线卡的转变在性能、灵活性和可伸展性方面提供了重要的益处。然而,它提出了必须由新的ASIC设计和软件解决的实施难题。 路由选择难题 ---- 路由所需的基本功能如下: ---- 全球因特网结构有许多内在灵活性和弹性,来自于它分段成一个逻辑上可设定地址的子网层次结构系统。子网与无类域间路由(CIDR)系统重叠,在CIDR系统中每个路由器经过它的可直接访问连接负责前向通信,将最终的逻辑地址信息(其形式为一个最长的地址前缀匹配)与当前CIDR路由表信息相对照,解决了局部路由决策。 ---- 然而,由于路由表变得更大和更加复杂,有许多层次结构的网络层,CIDR路由查找操作的复杂性可能显著增加,使所需查询时间呈对数增加。在集中化环境中,必须对这些路由处理功能进行紧密的管理,以确保诸如那些载送声音通信量的对延迟敏感包的确定性的等待时间。 ---- 依据预先确定的特征对包通信量进行识别和分组,包分类和流程处理功能为优化路由选择提供了一个关键的机制。分类和分组可能涉及不同的准则,比如将包与相似的源和目标IP地址进行匹配,依据特定的TCP/UCP套接字,或使用DiffServ代码识别包。 ---- 通常,在边缘路由选择环境中,流程处理决策所基于的粒度和特定性比中心环境中使用的程度更高。 ---- 中心环境中的时间限制和流量水平,要求路由决策应大大简化。为有效处理,将微流通信量群集成宏观流。因此,目前的体系结构趋向于为通过中心处的快速、有效地传送通信量预先做准备。 ---- 对异构环境来说,多协议标记交换(MPLS)提供了一个更高水平的路由和前向机制,这一机制将IP路由控制与第2层交换的简单性合并在一起。在一个有效的系统体系结构中,MPLS可以大大减小复杂性和将冗余协议层的需求减至最小。它也可以提高对不同类型通信量的QoS管理的能力。 传统体系结构 ---- 在传统的路由体系结构中,路由智能的大部分通常集中在系统级别的交换结构中,线卡本身中存在很少或不存在局部智能。在网络间组网的早期演变阶段,链接路由和用户数目相对较少,实际上所有的路由处理可以在软件内处理。 ---- 然而,随着网络在通信量水平和复杂性方面的增长,基于软件的路由器可能变为瓶颈。此外,传统的整体式体系结构通常缺乏平稳经济的可升级性,这是由于为了获取路由能力的下一次增加,有时必须对整个系统进行添加。 ---- 由于因特网通信量的增加,超过了T3线路的容量和现有的IP路由的能力,大部分骨干段使用OC-3、OC-12级别的交换ATM界面迁移至光纤连接,最终使用OC-48和OC-192级别迁移。虽然高速ATM交换重叠连接的使用为传送经封装的IP通信量提供了最可用的解决方案,但IP和ATM之间的协议转换需求增加了讨厌的复杂层和系统开销。 ---- 目前,随着全球化推广和接受IP作为事实上的组网协议,以及DWDM的出现为直接通过单波长传送IP通信量提供了潜在的可能,存在着实现十分流线型效率的可能。然而,将此可能变为资本,要求实现新的高性能和可经济升级的系统体系结构,此结构具有集成的QoS功能,它可以提供线卡级别上声音、视频和数据通信量专线速度的非阻塞路由选择。 对卡性能实现杠杆作用 ---- 新的系统通过将传统的路由器分割重新排列,使包处理和前向功能分布到线卡中,代替将它们集中在交换结构中。这可以消除路由器的中心处理资源的负担而集中于整体路由选择策略、路径发现、网络管理以及可靠性问题。 ---- 在这些分布式路由选择系统中,线卡担负整个路由器的作用,负责指定给它们的进口和出口界面。除了提供PMD和连接层功能外,这些卡也集成了对流程处理、QoS以及通信量设计功能进行处理的性能和智能。将这些对延迟敏感的功能从中央处理器中去除,线卡可以被优化为提供真正的线速路由选择,同时交换结构提供了线卡间无阻塞连接。(参见图1) 性能和可升级性 ---- 将功能分割到集中化的路径发现和分布式包处理中,使响应能力和资源效率达到最大化。典型条件下,路径发现功能需要的时间在10~100ms范围,而线速包处理和前向需要的响应时间可能快几个数量级。 ---- 例如,维持一个OC-48c连接电报速度的线速率,要求处理时间常数为1/129ns。试图将这些显然不同的要求揉合在一个整体IC卡内是一个次优化的方法。 ---- 另一个需要考虑的事项是分布式系统内在的升级性和可配置性。例如,在目前的异构环境中,服务提供商配置系统处理不同的线速度,如OC-3c,OC-12c和OC-48c,而后当需求增加和变化时,需要改变此配合,这种情况是非常普遍的。 ---- 在集中化包处理系统中,对处理负荷按比例增加和重新平衡的前景可能由艰难变得不可能。与此相反,在分布式系统中,包处理智能包含在每个线卡中,进/出接口的数目和组合可以简单地由增加线卡的方式来修改,而对交换结构很少需要或不需要进行调整。 冗余和强大性 ---- 分布式包处理除了提供改进的性能和伸展性,也提供了更加简单的冗余机制和更高水平的系统强大性。在传统的体系结构中,为集中化的包处理功能提供冗余的唯一方法是配置另外一个整体系统。另一方面,分布式体系结构仅通过复制单线卡就能够允许n+1的冗余度。 ---- 包处理功能分割到单线卡中除了改进了冗余度外,也有助于推进强大性和可靠性。这是通过消除所有的路由智能放入一个共享的交换结构中所带来的单点失效危险来实现的。路由智能的一个重要部分分割到容易替换的线卡中,维护成本、备件清单管理以及平均修理时间都可以得到改进。 实施难题 ---- 分布式包处理所带来的益处是巨大的,与智能线卡设计相关的难题也是如此。这种智能线卡仅在具有某种ASIC时才成为可能,此ASIC经特定优化,使包处理/前向与通信量形成集成在一起,同时提供可靠的延迟水平和QoS管理。 ---- 由于空间和能源变得日益局限在高端口密度的路由/交换系统中,智能线卡中使用的IC必须提供优化的功能集成,而能源消耗最小。为了优化包存储和前向功能(参见图2),对芯片内存的有效使用和芯片外内存的直接高速访问也是需要的。 ---- 为解决目前的需求,线卡IC必须提供至少两个全双工线路接口的能力。它们也应提供内置选项,以便对端口进行配置从而支持OC-3c,OC-12c和OC-48c物理接口的不同组合。 ---- 芯片处理能力应考虑多达256000个单流程分类,这些分类可以依据广泛的标准对包进行分类。这些标准包括IP源/目的地址、TCP/UDP信息、Diffserv代码、TCP控制位和数据报位。集成的包过滤器也应考虑在线卡级别上对不同的可编程动作进行触发和执行,如基于特定标准对包进行丢弃或重新标记。 ---- 硬件/固件支持也应提供线卡级别的选择,这些选择的范围包括不同的用户配置原则、排队以及通信量形成功能。举例来说,类似weighted-round- robin robin时序安排和weighted-fair时序安排的通信量设计替代方法应该是存在的,从而允许对路由策略进行修改以满足特定的需求。此外,芯片拥挤控制应可以通过类似随机早期侦测(RED)和丢弃过程来获得,从而依据软件可编程丢弃优先权准则对传送队列进行监控和管理。 展望 ---- 将包处理/前向和QoS功能分割到智能线卡中,除了提供即时性能和灵活性结果外,也为平稳前向迁移以处理类似OC-192 的较高带宽光学接口提供了可能。无需对整体系统级别的路由选择功能进行大规模的重新设计,新型光学接口可以直接通过相对简单的线卡重设计而自我调节,这可以维持与现有系统和交换结构的即插即用兼容性。
 图1:将路由/流程处理和队列管理从中心结构中移动到线卡中,这使线速的IP处理和便利对系统缩放成为可能。
图1:将路由/流程处理和队列管理从中心结构中移动到线卡中,这使线速的IP处理和便利对系统缩放成为可能。
----* 强大的线速的路由选择性能
----* 可靠的QoS管理
----* 灵活和可配置的通信量操纵性能
----* 满足未来需求平稳的和经济的可升级性
----* 路由处理,以确定包最终接收方。
----* 流程处理,以根据目前相关准则对包处理进行分类和确定优先次序。
----* 路径发现,以根据目前意识到现有拓扑和状态条件,确定包的合适路径。
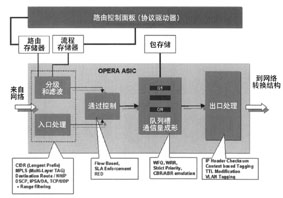 图2:将线卡路由处理集成在一个专用IC中,减少了能量消耗和板的面积,为未来升级预留空间。
图2:将线卡路由处理集成在一个专用IC中,减少了能量消耗和板的面积,为未来升级预留空间。
