数字信号处理学科与数字信号处理器
数字信号处理(DSP)自1965年由Cooley和Tukey提出DFT(离散傅里叶变换)的高效快速算法(Fourier Transform,简称FFT)以来,已有近40年的历史。随着计算机和信息技术的发展,数字信号处理技术已形成一门独立的学科系统。数字信号处理作为一门独立学科是围绕着三个方面迅速发展的:理论、现实和应用。作为数字信号理论,一般是指利用经典理论(如数字、信号与系统分析等)作为基础而形成的独特的信号处理理论,以及各种快速算法和各类滤波技术等基础理论。由此在各个应用领域如语音与图象处理、信息的压缩与编码、信号的调制与调解、信道的辨识与均衡、各种智能控制与移动通讯等都延伸出各自的理论与技术,到目前可以说凡是用计算机来处理各类信号的场合都引用了数字信号处理的基本理论、概念和技术。
数字化技术有今天的飞速发展,是依仗于强大的软、硬件环境支撑。作为数字信号处理的一个实际任务就是要求能够快速、高效、实时完成处理任务,这就要通过通用或专用的数字信号处理器来完成。因此,数字信号处理器是用来完成数字信号处理任务的一个软、硬件环境和硬件平台。
DSP算法及芯片分类
DSP运算的基本类型是乘法和累加(MAC)运算,对于卷积、相关、滤波和FFT基本上都是这一类运算。这样的运算可以用通用机来完成,但受到其成本和结构的限制不可能有很高的实时处理能力。
DSP运算的特点是寻址操作。数据寻址范围大,结构复杂但很有规律。例如FFT运算,它的蝶形运算相关节点从相邻两点直至跨越N/2间隔的地址范围,每次变更都很有规律,级间按一定规律排列,虽然要运算log2N遍,但每级的地址都可以预测,也就是寻址操作很有规律而且可以预测。这就不同于一般的通用机,在通用机中对数据库的操作,具有很大的随机性,这种随机寻址方式不是信号处理器的强项。
可以看出无论是专用的DSP芯片或通用DSP芯片在结构考虑上都能适应DSP运算的这些特点。而专用芯片在结构上考虑的更加专业化,更为合理,因而有更高的运算速度。
DSP芯片按用途或构成分类可以分为下列几种类型: 为不同算法而专门设计的专用芯片:例如用于做卷积/相关并具有横向滤波器结构: INMOS公司的A100、A110;HARRIS公司的HPS43168; PLESSY GEC 公司的PDSP16256等。 用于做FFT: Austek公司的A41102, PLESSY GEC 公司的PDSP16150等。这些都是为做FIR、IIR、FFT运算而设计的,因而运算速度高,但是具有有限的可编程能力,灵活性差。
为某种目的应用的专门设计系统,即ASIC系统。它只涉及一种或一种以上自然类型数据的处理,例如音频、视频、语音的压缩和解压,调制/解调器等。其内部都是由基本DSP运算单元构建,包括FIR、IIR、FFT、DCT,以及卷积码的编/解码器及RS编/解码器等。其特点是计算复杂而且密集,数据量、运算量都很大。
积木式结构:它是由乘法器、存储器、控制电路等单元逻辑电路搭接而成,这种结构方式也称为硬连线逻辑电路。它是一种早期实现方法,具有成本低、速度高等特点,由于是硬连接因而没有可编程能力。目前主要用于接收机的前端某些高频操作中。
用FPGA(现场可编程陈列)实现DSP的各
种功能。实质上这也是一种硬连接逻辑电路,但由于有现场可编程能力,允许根据需要迅速重新组合基础逻辑来满足使用要求,因而更加灵活,而且比通用DSP芯片具有更高的速度。一些大的公司如 Xinlinx、Altera也正把FPGA产品扩展到DSP应用中去。通用可编程DSP芯片:这是目前用得最多的数字信号处理应用器件,其特点本文将予以详细讨论。
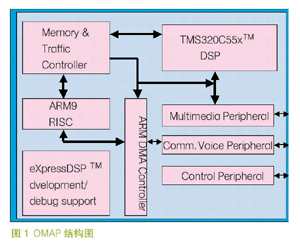
片上系统Soc(System on Chip),这是数字化应用及微电子技术迅速发展的产物,是下一代基于DSP产品的主要发展方向之一。它把一种应用系统集成在一个芯片上。通常,为满足系统的性能要求和提高功率效率,会把DSP和MCU的多处理器处理平台集成在一起。图1 是由TI公司推出的开放多媒体应用平台(OMAP),用来支持2.5G和3G应用而设计的处理器体系结构,它支持语音、音频、图像和视频信号处理应用的各种性能。其中关键器件有:低功耗的DSP芯片,用来做媒体处理;MCU用来支持应用操作系统及以控制为核心的应用处理;MTC是内存和流量控制器,确保处理器能高效访问外部存储区,避免产生瓶颈现象,提高整个平台的处理速度。
DSP对MCU性能上的改进
对数字信号处理器可以确切的下这样的定义:解决实时处理要求,适合DSP运算需求的单片可编程微处理器芯片。原理上说通用微机、单片机都可以用来做信号处理的硬件平台,但作为DSP实时处理要求必须满足大数据量、复杂计算、实时性强的各种运算,因而DSP芯片针对DSP算法特点做了以下几方面的改进:
运算能力上的扩充
采用专用的硬件乘法器,有足够的字长,乘法结果保留全部数值,用双字长乘法存储器,同时可以用来做双精度运算。
自动产生数据地址
通用处理器由ALU产生地址,在DSP中专门有地址产生单元,通过程序循环,自动产生数据地址,这一单元本身也是一个微处理器,可以通过编程产生复杂的非顺序地址(例如FFT中的倒位序地址产生)。
指令时序的产生不对其他运算单元造成额外开销
指令时序是可编程的,在遇到执行程序转移和循环时,不会额外增加开销。
简单比例定标运算得到宽的动态范围
一般DSP芯片中都有桶形移位器,可以在一定范围内调整数据输出宽度,特别是在做浮点和块浮点运算时,免去主处理器作多次移位和旋转操作。
DSP处理器特点
DSP处理器的着眼点是要求速度快、处理的数据量大、效率高。但是单纯提高时钟速度受到工艺等各种因素的限制,一般是缓慢的,所以必须从结构上着手。某些概念其实在二十世纪40年代已经出现:其一是改造处理器的处理方法,用多总线、多存储器体系结构;其二是提高程序和数据流的速度,采用流水线,并行处理等方法。尽管不同厂商采用不同的技术和措施,但在这些方面都有共同点。以下就DSP芯片一些特点来作说明。
采用哈佛(Harvard)结构和改进的哈佛结构
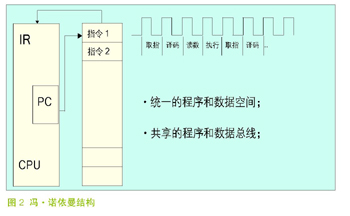
通用机采用冯·诺依曼(Von Neumenn)结构,这主要考虑到成本,其结构如图 2 所示。把指令、数据、地址的传送采用同一条总线,靠指令计数来区分三者。由于取指和存取数据是在同一存取空间通过同一总线传输,因而指令的执行只能是顺序的,不可能重叠进行,所以无法提高运算速度。
DSP处理器几乎毫无例外的采用哈佛结构,如图3所示。哈佛结构把程序代码和数据的存储空间分开,并有各自的地址和数据总线,每个存储器独立编址,用独立的一组程序总线和数据总线进行访问。
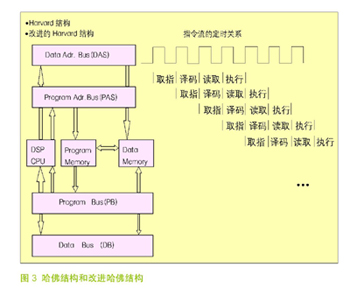
如果程序代码存储空间与数据存储空间之间还可以进行数据交换,则称为改进的哈佛结构。这种结构可以并行进行数据操作。例如在做数字滤波时把系数放在程序空间,待处理的样本数据放在数据空间,处理时可以同时提取滤波器系数和样本进行乘法和累加操作,从而大大提高运算速度。 改进哈佛结构还可以从程序存储区来初始化数据存储区,或把数据存储区的内容转移到程序存储区,这样可以复用存储器,降低成本,提高存储器使用效率。
多总线结构
例如TMS320C54X结构中有一组程序总线(PB PAB),两组读数据总线(CB CAB)、(DB DAB),和一组写数据总线(EB EAB),这样可以同时读取两组数据和存储一组数据,即同一时钟周期内可以执行一条3个操作的指令。这种附加总线和扩充地址增加数据流量,提高寻址能力。
采用流水线操作
计算机在执行一条指令时,要通过取指、译码、取数、执行等各阶段。由于DSP哈佛结构指令的各个阶段可以重叠进行,这样对每一条指令似乎都是在一个周期内完成,可以把指令周期减到最小,增加数据吞吐量。
这种流水线操作也不是十全十美的,其主要原因是,一项处理很难被分解成若干个处理规模一致、在时间上有最佳配合的流水段,因而需要用寄存器协调流水线工作。
流水线操作适用于循环操作时间足够长或多个数据点反复执行同一指令的情况。这是由于,流水线启动和停止的阶段是流水线逐步被填满和出空的过程。对于一次性非重复计算,流水线不可能达到稳态,反而用主要时间做填满和出空操作,因而是不合适的。
硬件乘法器和高效的MAC指令
在DSP算法中,乘法累加操作是大量的运算。因而DSP芯片都有硬件乘法器,使得乘法运算做到一个周期内完成。与之配合的指令为MAC-乘法累加指令,其功能如图 4 所示,它可以在单周期内取两个操作数相乘,并将结果加载到累加器。有的DSP还具有多组MAC结构,可以并行处理。
独立的传输总线及其控制器
处理器高速处理速度必须与高速的数据访问和传输相配合。而且为不影响CPU及其相关总线的工作,DSP的DMA单独设置了传输总线及其控制器,因此DMA可以独立工作。
为了提高DSP的实时处理能力,有时把多个DSP组成DSP处理器阵列,并行工作,此时DMA成为各处理器之间进行数据传输的主要通道。
专用的数据地址发生器(DAG)
在DSP运算中,存储器的访问具有可预测性。例如在FIR滤波中,样本、系数都是顺序访问的,因此在DSP芯片中专门设置数据地址发生器。其实它也是一个ALU单元,具有简单的运算能力。在通用机的CPU中,数据地址和数据处理都由同一ALU完成。例如在8086
中,做一次加法需要三个周期,而计算一次地址需要5~6 周期,这样会耗费大量的时间。在DSP芯片中就不需要这样的额外开销。另外在DSP芯片的数据地址产生中还支持间接寻址、循环寻址、倒位寻址等特殊操作,以适应DSP运算的各种寻址需求。 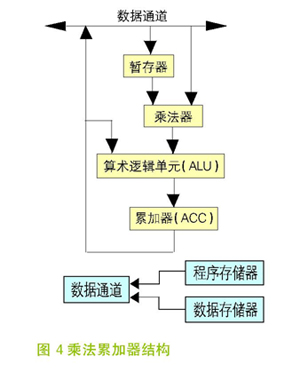
丰富的外设(Peripherals)
DSP处理器往往是脱机独立工作,因此为与外设接口方便,往往设置了丰富的周边接口电路。一般包含下列几种主要外设:
时钟产生器(振荡器与锁相环PLL);
定时器(Timer);
软件可编程等待状态发生器,以便使较快的片内设施与较慢的片外电路及存储器协调工作;
通用的I/O口;
多通道同步缓冲串口(McBSP)和异步串口;
主机接口(HIP)
JTAG边界扫描逻辑电路(IEEE 标准1149. 1),便于对DSP处理器做片上在线仿真和多处理器情况下的调试。
具有片内存储器
DSP芯片片内一般带有存放程序的只读存储器ROM和存放数据的随机存储器RAM,符合DSP运算简单、核心程序短小的特征,同时可以提高指令传输效率,减小总线接口压力。并且它不存在与外部总线竞争和访问外部存储器速度不匹配的问题,这样使DSP处理器具有强大的数据处理能力。
与结构相配合的采用RISC指令集
一般DSP处理器具有高度专门化、复杂且不规则的指令集,这样单个指令字可以同时控制片内多个功能单元操作。DSP处理器指令集在设计时有两个特点:其一是最大限度的使用了处理器的硬件资源,因此往往是在单个指令中并行完成若干操作。例如在完成主要算术运算的同时,并行地从存储器提取一个或两个数据以及完成地址指针的更新。其次是指令所使用的存储空间减到最小,为缩短指令字长,往往用状态寄存器的模式来控制处理器的操作特性,例如舍入或饱和的处理,而不再将这些信息作为指令的一部分来处理。
由于传统DSP芯片指令集的高度专门化及多功能操作使它难以用高级语言编译,所以一般C编译效率不高。另外C语言也不适合用来描述这种多存储空间、多组总线、高度专门化结构的硬件系统,这些都是导致用C编译传统DSP处理器效率不高的原因。
综上所述DSP处理器实现高速运算的主要途径可以概括为:具有硬件乘法器及乘-加单元;高效的存储器访问;零开销循环;专门的适应硬件结构的指令集;多执行单元;数据流的线性I/O口。
DSP处理器性能指标
对DSP处理器缺乏一种诸如对PC机那样公正合理的性能评价体系,这是由于各DSP厂商推出的产品在结构和数据传输能力上有很大的差异,它是专门为某种目的而设计的,因而正确评价只有与特定的应用联系起来,评价结果才有意义。这里将常用的指标评价方法做一介绍。
传统评价方法,这是最简单的评价指标:
MIPS(Millions of Instructions Per Seco
nd),一般DSP为20~100MIPS,使用超长指令字的TMS320B2XX为2400MIPS。MFLOaPS(Million Floating Point Operations Per Second),这是衡量浮点DSP芯片的重要指标。例如TMS320C31在主频为40MHZ时,处理能力为40MFLOPS,TMS320C6701在指令周期为6ns时,单精度运算可达1GFLOPS。
MBPS(Million Bit Per Second),它是对总线和I/O口数据吞吐率的度量,也就是某个总线或I/O的带宽。例如对TMS320C6XXX、200MHZ时钟、32bit总线时,总线数据吞吐率则为800Mbyte/s或6400MBPS。
MACS(Multiply-Accumulates Per Second),例如TMS320C6XXX乘加速度达300MMACS~600MMACS。
以上传统指标虽然可以作为设计时可选的参考指标,但是有很大的局限性。例如它没有考虑存储器的使用和器件的功耗,一旦器件与外部速度较慢的存储器进行数据交换时,运行速度马上就会被降低。
另一评价指标是核心算法评价指标。它是利用构成大多数DSP系统的基本运算模块,例如FIR、IIR、FFT、向量加等典型运算。规定大小适度、统一输入、输出要求,在保证功能一致性的条件下,也允许程序员针对所使用的处理进行代码的优化,评价指标是执行时间、存储器的使用和能耗等。
表1是对一些处理器评价的结果,其中DSP53611和MSC8101是MOTOROLA产品,TMS320C5416\6203是TI公司产品。TMS320C6701和Pentium Ⅲ属于浮点运算。
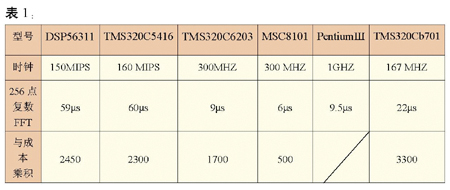
这种评价方法很容易用软件仿真或基于硬件应用的开发工具来决定执行的周期数。
从上列执行时间可以看出处理器结构对其性能的影响。例如TMS320C6203,时钟300MHZ,由于采用超长指令字结构、每个指令周期内处理8条指令,因此等效为2400MIPS,与TMS320C5416相比MIPS之比为15:1。但执行同样的256点复数FFT所需时间之比为7.8:1,因此两者用MIPS作为比较指标就有差距。其原因是C6203指令比C5416简单,因而完成同样任务需要更多的指令,另外也由于数据的独立和流水作业的影响等因素,C6203的并行性不能同时得到最佳的发挥。并且,这种核心算法评估指标并没有反映出计算精度,提高计算精度意味着字长的增加或采用浮点运算,相应的存储器容量增加,这些情况都没有能在指标中反映。
DSP处理器还有其他评估指标,各类评估指标之间都有其自身的不足,因而正确的选用器件要根据任务需要量身定做,不可一味追求某项高指标,要根据性能价格比合理选用器件。
